 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Rollout Allocation for Online Reinforcement Learning with Verifiable Rewards
Feb 03, 2026Sampling efficiency is a key bottleneck in reinforcement learning with verifiable rewards. Existing group-based policy optimization methods, such as GRPO, allocate a fixed number of rollouts for all training prompts. This uniform allocation implicitly treats all prompts as equally informative, and could lead to inefficient computational budget usage and impede training progress. We introduce VIP, a Variance-Informed Predictive allocation strategy that allocates a given rollout budget to the prompts in the incumbent batch to minimize the expected gradient variance of the policy update. At each iteration, VIP uses a lightweight Gaussian process model to predict per-prompt success probabilities based on recent rollouts. These probability predictions are translated into variance estimates, which are then fed into a convex optimization problem to determine the optimal rollout allocations under a hard compute budget constraint. Empirical results show that VIP consistently improves sampling efficiency and achieves higher performance than uniform or heuristic allocation strategies in multiple benchmarks.
Optimizing Agentic Reasoning with Retrieval via Synthetic Semantic Information Gain Reward
Jan 31, 2026Agentic reasoning enables large reasoning models (LRMs) to dynamically acquire external knowledge, but yet optimizing the retrieval process remains challenging due to the lack of dense, principled reward signals. In this paper, we introduce InfoReasoner, a unified framework that incentivizes effective information seeking via a synthetic semantic information gain reward. Theoretically, we redefine information gain as uncertainty reduction over the model's belief states, establishing guarantees, including non-negativity, telescoping additivity, and channel monotonicity. Practically, to enable scalable optimization without manual retrieval annotations, we propose an output-aware intrinsic estimator that computes information gain directly from the model's output distributions using semantic clustering via bidirectional textual entailment. This intrinsic reward guides the policy to maximize epistemic progress, enabling efficient training via Group Relative Policy Optimxization (GRPO). Experiments across seven question-answering benchmarks demonstrate that InfoReasoner consistently outperforms strong retrieval-augmented baselines, achieving up to 5.4% average accuracy improvement. Our work provides a theoretically grounded and scalable path toward agentic reasoning with retrieval.
VP-Bench: A Comprehensive Benchmark for Visual Prompting in Multimodal Large Language Models
Nov 14, 2025Multimodal large language models (MLLMs) have enabled a wide range of advanced vision-language applications, including fine-grained object recognition and contextual understanding. When querying specific regions or objects in an image, human users naturally use "visual prompts" (VPs), such as bounding boxes, to provide reference. However, no existing benchmark systematically evaluates the ability of MLLMs to interpret such VPs. This gap leaves it unclear whether current MLLMs can effectively recognize VPs, an intuitive prompting method for humans, and use them to solve problems. To address this limitation, we introduce VP-Bench, a benchmark for assessing MLLMs' capability in VP perception and utilization. VP-Bench employs a two-stage evaluation framework: Stage 1 examines models' ability to perceive VPs in natural scenes, using 30k visualized prompts spanning eight shapes and 355 attribute combinations. Stage 2 investigates the impact of VPs on downstream tasks, measuring their effectiveness in real-world problem-solving scenarios. Using VP-Bench, we evaluate 28 MLLMs, including proprietary systems (e.g., GPT-4o) and open-source models (e.g., InternVL3 and Qwen2.5-VL), and provide a comprehensive analysis of factors that affect VP understanding, such as variations in VP attributes, question arrangement, and model scale. VP-Bench establishes a new reference framework for studying how MLLMs comprehend and resolve grounded referring questions.
From Exploration to Exploitation: A Two-Stage Entropy RLVR Approach for Noise-Tolerant MLLM Training
Nov 11, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) for Multimodal Large Language Models (MLLMs) is highly dependent on high-quality labeled data, which is often scarce and prone to substantial annotation noise in real-world scenarios. Existing unsupervised RLVR methods, including pure entropy minimization, can overfit to incorrect labels and limit the crucial reward ranking signal for Group-Relative Policy Optimization (GRPO). To address these challenges and enhance noise tolerance, we propose a novel two-stage, token-level entropy optimization method for RLVR. This approach dynamically guides the model from exploration to exploitation during training. In the initial exploration phase, token-level entropy maximization promotes diverse and stochastic output generation, serving as a strong regularizer that prevents premature convergence to noisy labels and ensures sufficient intra-group variation, which enables more reliable reward gradient estimation in GRPO. As training progresses, the method transitions into the exploitation phase, where token-level entropy minimization encourages the model to produce confident and deterministic outputs, thereby consolidating acquired knowledge and refining prediction accuracy. Empirically, across three MLLM backbones - Qwen2-VL-2B, Qwen2-VL-7B, and Qwen2.5-VL-3B - spanning diverse noise settings and multiple tasks, our phased strategy consistently outperforms prior approaches by unifying and enhancing external, internal, and entropy-based methods, delivering robust and superior performance across the board.
Better Reasoning with Less Data: Enhancing VLMs Through Unified Modality Scoring
Jun 10, 2025

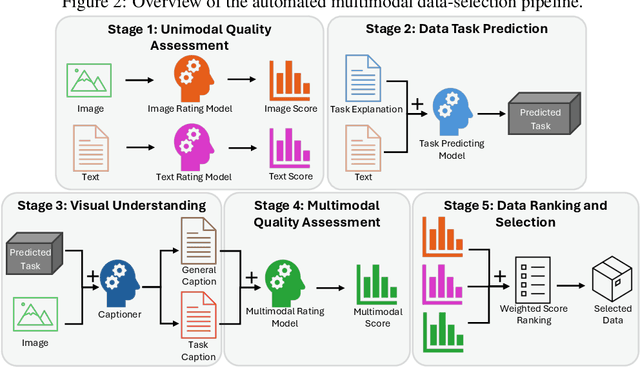

The application of visual instruction tuning and other post-training techniques has significantly enhanced the capabilities of Large Language Models (LLMs) in visual understanding, enriching Vision-Language Models (VLMs) with more comprehensive visual language datasets. However, the effectiveness of VLMs is highly dependent on large-scale, high-quality datasets that ensure precise recognition and accurate reasoning. Two key challenges hinder progress: (1) noisy alignments between images and the corresponding text, which leads to misinterpretation, and (2) ambiguous or misleading text, which obscures visual content. To address these challenges, we propose SCALE (Single modality data quality and Cross modality Alignment Evaluation), a novel quality-driven data selection pipeline for VLM instruction tuning datasets. Specifically, SCALE integrates a cross-modality assessment framework that first assigns each data entry to its appropriate vision-language task, generates general and task-specific captions (covering scenes, objects, style, etc.), and evaluates the alignment, clarity, task rarity, text coherence, and image clarity of each entry based on the generated captions. We reveal that: (1) current unimodal quality assessment methods evaluate one modality while overlooking the rest, which can underestimate samples essential for specific tasks and discard the lower-quality instances that help build model robustness; and (2) appropriately generated image captions provide an efficient way to transfer the image-text multimodal task into a unified text modality.
SEFE: Superficial and Essential Forgetting Eliminator for Multimodal Continual Instruction Tuning
May 05, 2025Multimodal Continual Instruction Tuning (MCIT) aims to enable Multimodal Large Language Models (MLLMs) to incrementally learn new tasks without catastrophic forgetting. In this paper, we explore forgetting in this context, categorizing it into superficial forgetting and essential forgetting. Superficial forgetting refers to cases where the model's knowledge may not be genuinely lost, but its responses to previous tasks deviate from expected formats due to the influence of subsequent tasks' answer styles, making the results unusable. By contrast, essential forgetting refers to situations where the model provides correctly formatted but factually inaccurate answers, indicating a true loss of knowledge. Assessing essential forgetting necessitates addressing superficial forgetting first, as severe superficial forgetting can obscure the model's knowledge state. Hence, we first introduce the Answer Style Diversification (ASD) paradigm, which defines a standardized process for transforming data styles across different tasks, unifying their training sets into similarly diversified styles to prevent superficial forgetting caused by style shifts. Building on this, we propose RegLoRA to mitigate essential forgetting. RegLoRA stabilizes key parameters where prior knowledge is primarily stored by applying regularization, enabling the model to retain existing competencies. Experimental results demonstrate that our overall method, SEFE, achieves state-of-the-art performance.
ICM-Assistant: Instruction-tuning Multimodal Large Language Models for Rule-based Explainable Image Content Moderation
Dec 24, 2024



Controversial contents largely inundate the Internet, infringing various cultural norms and child protection standards. Traditional Image Content Moderation (ICM) models fall short in producing precise moderation decisions for diverse standards, while recent multimodal large language models (MLLMs), when adopted to general rule-based ICM, often produce classification and explanation results that are inconsistent with human moderators. Aiming at flexible, explainable, and accurate ICM, we design a novel rule-based dataset generation pipeline, decomposing concise human-defined rules and leveraging well-designed multi-stage prompts to enrich short explicit image annotations. Our ICM-Instruct dataset includes detailed moderation explanation and moderation Q-A pairs. Built upon it, we create our ICM-Assistant model in the framework of rule-based ICM, making it readily applicable in real practice. Our ICM-Assistant model demonstrates exceptional performance and flexibility. Specifically, it significantly outperforms existing approaches on various sources, improving both the moderation classification (36.8\% on average) and moderation explanation quality (26.6\% on average) consistently over existing MLLMs. Code/Data is available at https://github.com/zhaoyuzhi/ICM-Assistant.
Modeling Dual-Exposure Quad-Bayer Patterns for Joint Denoising and Deblurring
Dec 10, 2024



Image degradation caused by noise and blur remains a persistent challenge in imaging systems, stemming from limitations in both hardware and methodology. Single-image solutions face an inherent tradeoff between noise reduction and motion blur. While short exposures can capture clear motion, they suffer from noise amplification. Long exposures reduce noise but introduce blur. Learning-based single-image enhancers tend to be over-smooth due to the limited information. Multi-image solutions using burst mode avoid this tradeoff by capturing more spatial-temporal information but often struggle with misalignment from camera/scene motion. To address these limitations, we propose a physical-model-based image restoration approach leveraging a novel dual-exposure Quad-Bayer pattern sensor. By capturing pairs of short and long exposures at the same starting point but with varying durations, this method integrates complementary noise-blur information within a single image. We further introduce a Quad-Bayer synthesis method (B2QB) to simulate sensor data from Bayer patterns to facilitate training. Based on this dual-exposure sensor model, we design a hierarchical convolutional neural network called QRNet to recover high-quality RGB images. The network incorporates input enhancement blocks and multi-level feature extraction to improve restoration quality. Experiments demonstrate superior performance over state-of-the-art deblurring and denoising methods on both synthetic and real-world datasets. The code, model, and datasets are publicly available at https://github.com/zhaoyuzhi/QRNet.
LLaVA-SpaceSGG: Visual Instruct Tuning for Open-vocabulary Scene Graph Generation with Enhanced Spatial Relations
Dec 09, 2024



Scene Graph Generation (SGG) converts visual scenes into structured graph representations, providing deeper scene understanding for complex vision tasks. However, existing SGG models often overlook essential spatial relationships and struggle with generalization in open-vocabulary contexts. To address these limitations, we propose LLaVA-SpaceSGG, a multimodal large language model (MLLM) designed for open-vocabulary SGG with enhanced spatial relation modeling. To train it, we collect the SGG instruction-tuning dataset, named SpaceSGG. This dataset is constructed by combining publicly available datasets and synthesizing data using open-source models within our data construction pipeline. It combines object locations, object relations, and depth information, resulting in three data formats: spatial SGG description, question-answering, and conversation. To enhance the transfer of MLLMs' inherent capabilities to the SGG task, we introduce a two-stage training paradigm. Experiments show that LLaVA-SpaceSGG outperforms other open-vocabulary SGG methods, boosting recall by 8.6% and mean recall by 28.4% compared to the baseline. Our codebase, dataset, and trained models are publicly accessible on GitHub at the following URL: https://github.com/Endlinc/LLaVA-SpaceSGG.
Bidirectionally Deformable Motion Modulation For Video-based Human Pose Transfer
Jul 18, 2023



Video-based human pose transfer is a video-to-video generation task that animates a plain source human image based on a series of target human poses. Considering the difficulties in transferring highly structural patterns on the garments and discontinuous poses, existing methods often generate unsatisfactory results such as distorted textures and flickering artifacts. To address these issues, we propose a novel Deformable Motion Modulation (DMM) that utilizes geometric kernel offset with adaptive weight modulation to simultaneously perform feature alignment and style transfer. Different from normal style modulation used in style transfer, the proposed modulation mechanism adaptively reconstructs smoothed frames from style codes according to the object shape through an irregular receptive field of view. To enhance the spatio-temporal consistency, we leverage bidirectional propagation to extract the hidden motion information from a warped image sequence generated by noisy poses. The proposed feature propagation significantly enhances the motion prediction ability by forward and backward propagation. Both quantitative and qualitative experimental results demonstrate superiority over the state-of-the-arts in terms of image fidelity and visual continuity. The source code is publicly available at github.com/rocketappslab/bdmm.